|
I am a Member of Technical Staff at xAI, where I work on Grok Imagine Video Generation. I lead efforts in video pretraining & post-training data mixture, captioning, and training recipes. I build scalable highest quality in-house video generation dataset pipelines for the Grok Imagine Video base model and downstream tasks (editing, reference-guided, super-resolution, etc.). I received my Ph.D. and M.S.E. degrees in Computer Science from Johns Hopkins University, where I was advised by Bloomberg Distinguished Professor Dr. Alan Yuille. Before this, I got B.E. in Mechanical Engineering and Double Degree in Mathematics from Beihang University.
|

|
|
|
|
|
|
arXiv /
project page /
code /
bibtex
@inproceedings{chou2026captainsafari,
title={Captain Safari: A World Engine},
author={Chou, Yu-Cheng and Wang, Xingrui and Li, Yitong and Wang, Jiahao and Liu, Hanting and Xie, Cihang and Yuille, Alan and Xiao, Junfei},
booktitle={CVPR},
year={2026}
}
|
|
|
arXiv /
project page /
bibtex
@inproceedings{xiao2025captain,
title={Captain Cinema: Towards Short Movie Generation},
author={Xiao, Junfei and Yang, Ceyuan and Zhang, Lvmin and Cai, Shengqu and Zhao, Yang and Guo, Yuwei and Wetzstein, Gordon and Agrawala, Maneesh and Yuille, Alan and Jiang, Lu},
booktitle={ICLR},
year={2025}
}
|
|
|
paper /
project page /
bibtex
@article{xiao2024narrative,
title={Towards Long Narrative Video Generation},
author={Xiao, Junfei and Cheng, Feng and Qi, Lu and Gui, Liangke and Cen, Jiepeng and Ma, Zhibei and Yuille, Alan and Jiang, Lu},
journal={arXiv preprint},
year={2024}
}
|
|
|
arXiv /
project page /
bibtex
@article{lu2024genex,
title={GenEx: Generating an Explorable World},
author={Lu, Taiming and Shu, Tianmin and Xiao, Junfei and Ye, Luoxin and Wang, Jiahao and Peng, Cheng and Wei, Chen and Khashabi, Daniel and Chellappa, Rama and Yuille, Alan and Chen, Jieneng},
journal={arXiv preprint arXiv:2412.09624},
year={2024}
}
|
|
|
project page /
bibtex
@inproceedings{cai2025moc,
title={Mixture of Contexts for Long Video Generation},
author={Cai, Shengqu and Yang, Ceyuan and Zhang, Lvmin and Guo, Yuwei and Xiao, Junfei and Yang, Ziyan and Xu, Yinghao and Yang, Zhenheng and Yuille, Alan and Guibas, Leonidas and Agrawala, Maneesh and Jiang, Lu and Wetzstein, Gordon},
booktitle={ICLR},
year={2025}
}
|
|

|
arXiv /
code /
huggingface /
dataset /
bibtex
@inproceedings{zhang2025vlv,
title={VLV: Vision-Language-Vision Auto-Encoder: Scalable Knowledge Distillation from Diffusion Models},
author={Zhang, Tiezheng and Li, Yitong and Chou, Yu-cheng and Chen, Jieneng and Yuille, Alan L and Wei, Chen and Xiao, Junfei},
booktitle={NeurIPS},
year={2025}
}
|
|
arXiv /
project page /
code /
bibtex
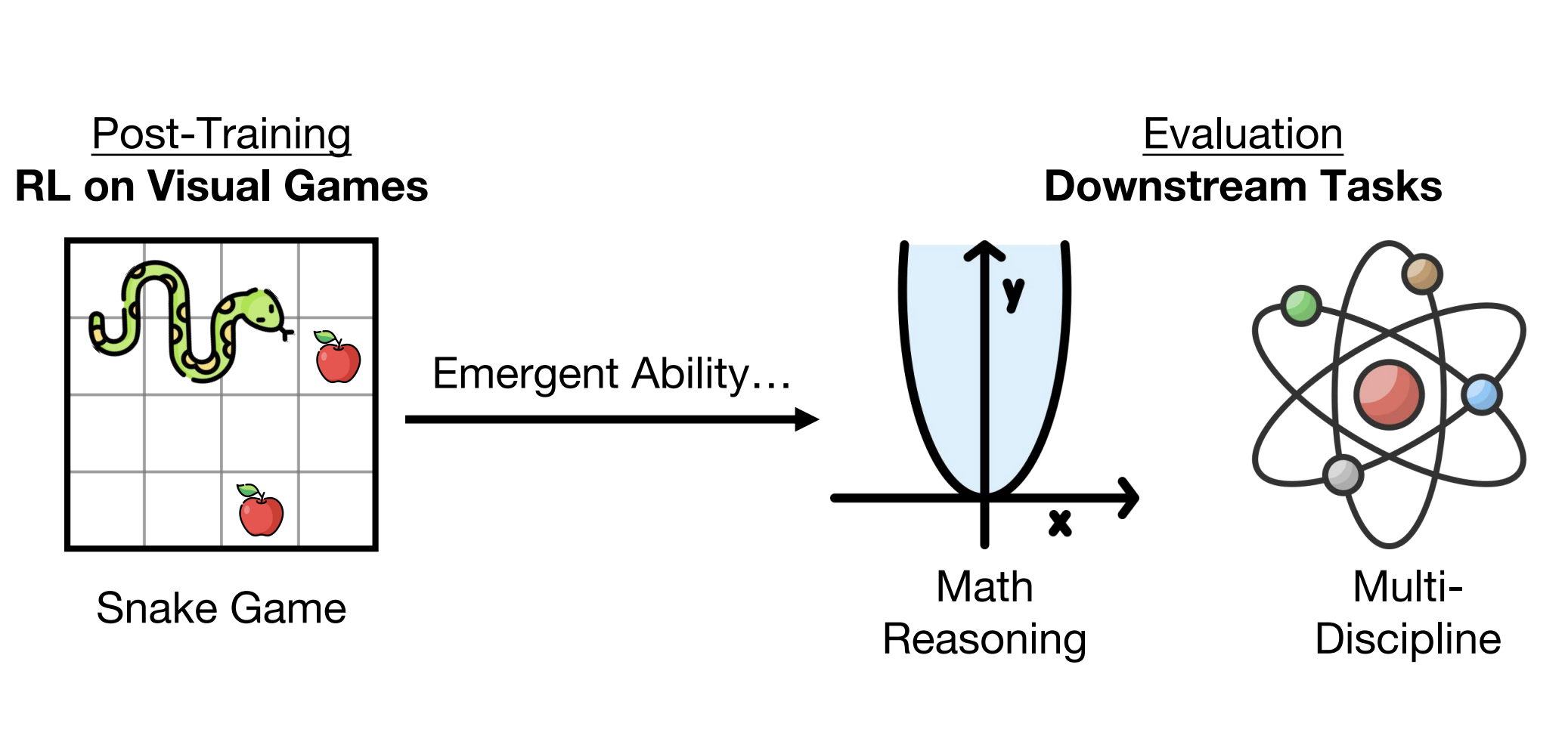
@article{xie2025vigal,
title={Play to Generalize: Learning to Reason Through Game Play},
author={Xie, Yunfei and Ma, Yinsong and Lan, Shiyi and Yuille, Alan and Xiao, Junfei and Wei, Chen},
journal={ICLR},
year={2025}
}
|
|
arXiv /
slides /
bibtex
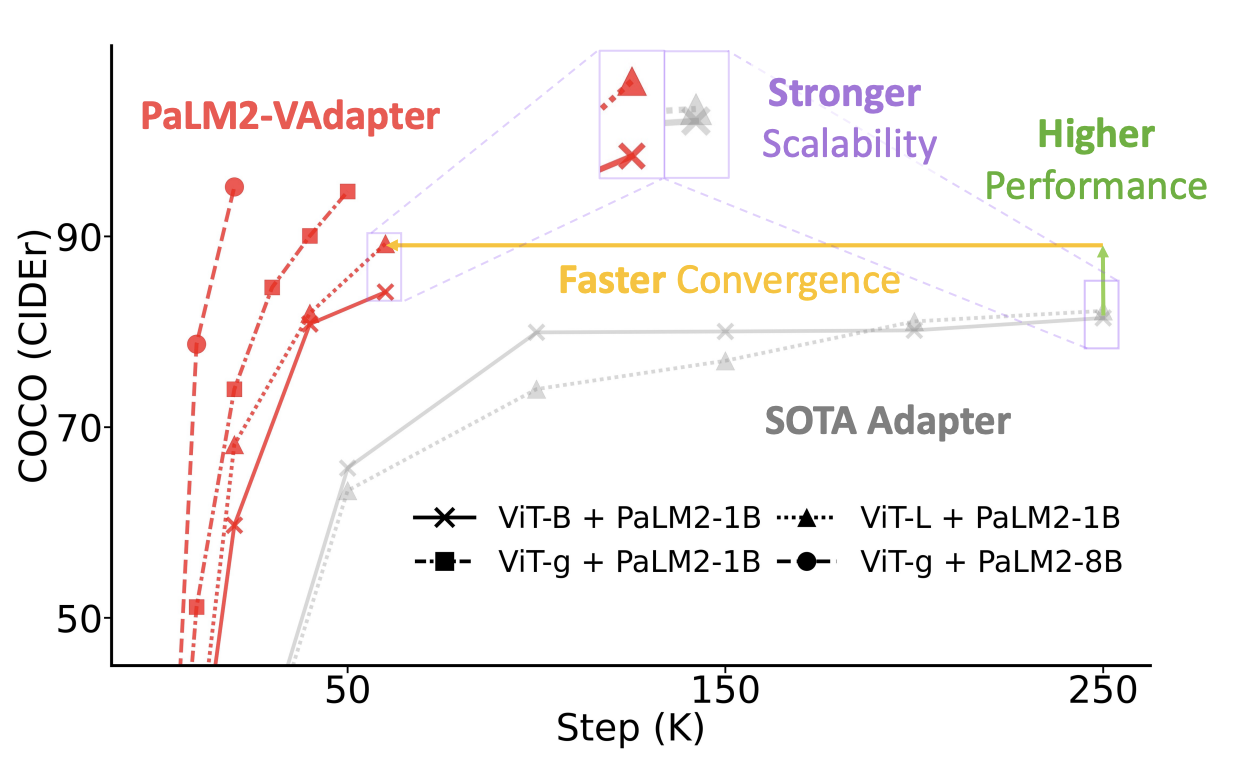
@article{palm2vadapter2024,
title={PaLM2-VAdapter: Progressively Aligned Language Model Makes a Strong Vision-language Adapter},
author={Xiao, Junfei and Xu, Zheng and Yuille, Alan and Yan, Shen and Wang, Boyu},
journal={arXiv preprint arXiv:2402.10896},
year={2024},
}
|
|
arXiv /
code /
bibtex
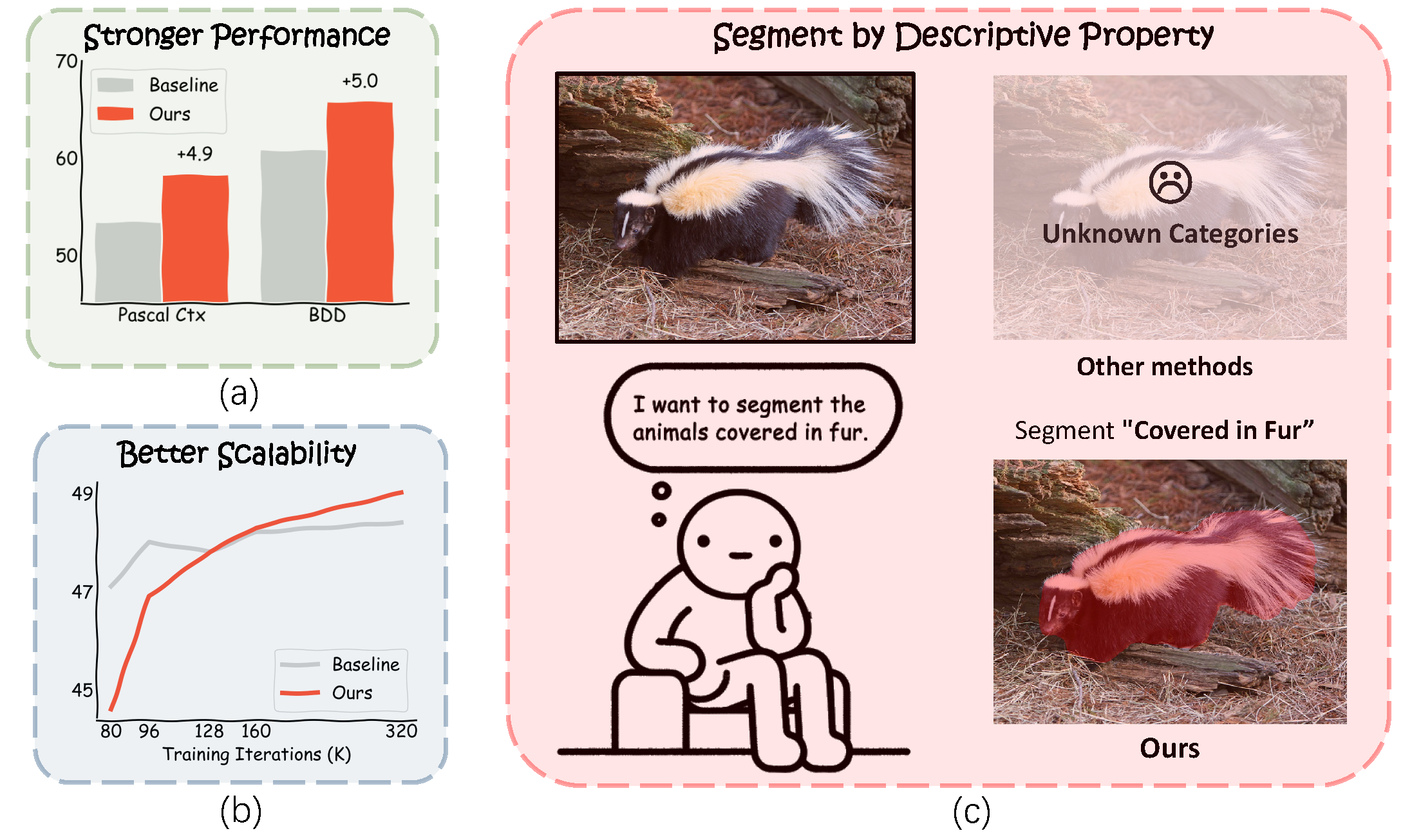
@article{xiao2023semantic,
author = {Xiao, Junfei and Zhou, Ziqi and Li, Wenxuan and Lan, Shiyi and Mei, Jieru and Yu, Zhiding and Yuille, Alan and Zhou, Yuyin and Xie, Cihang},
title = {A Semantic Space is Worth 256 Language Descriptions: Make Stronger Segmentation Models with Descriptive Properties},
journal = {arXiv preprint arXiv:2312.13764},
year = {2023},
}
|
|
arXiv /
code /
bibtex
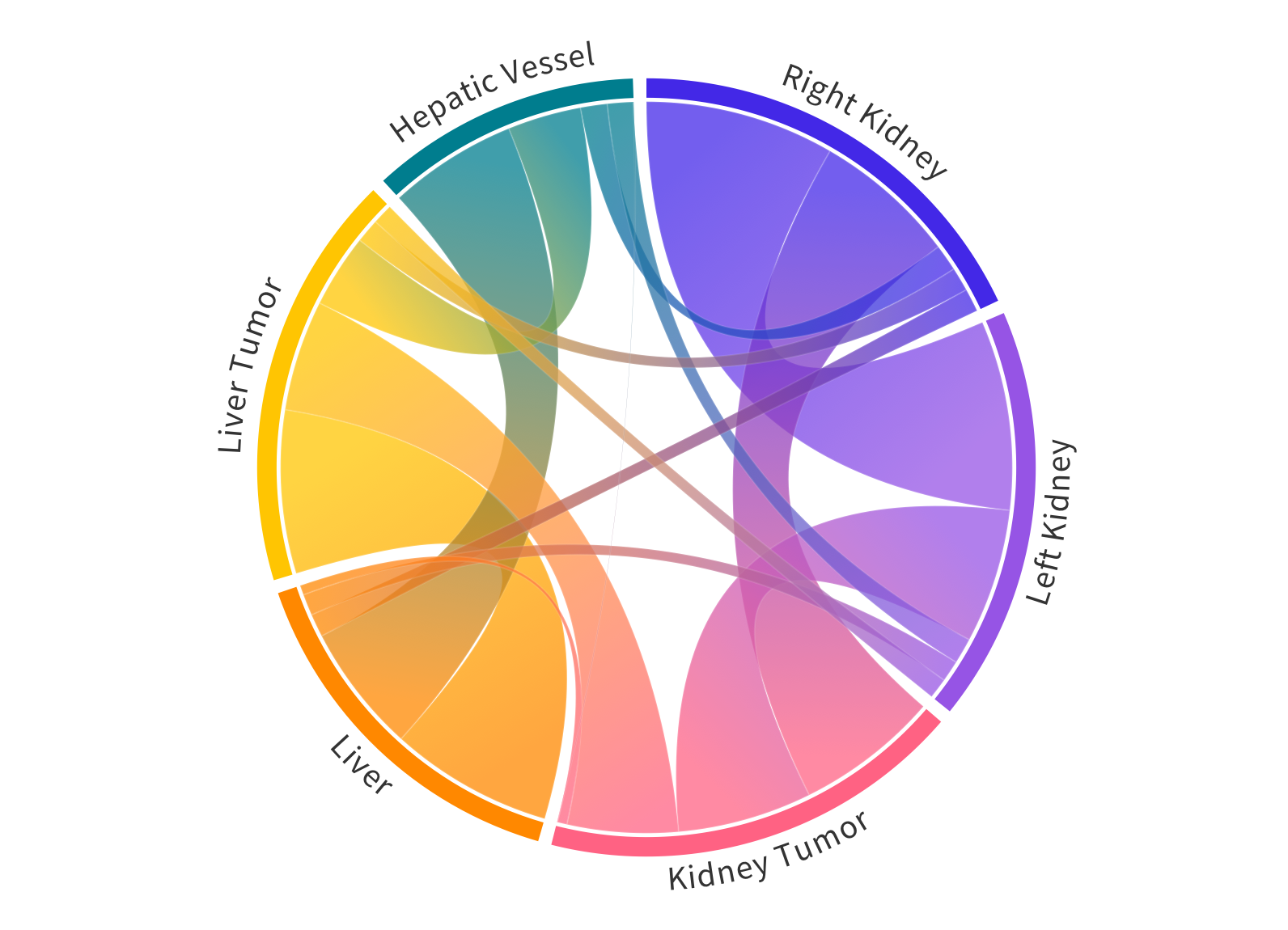
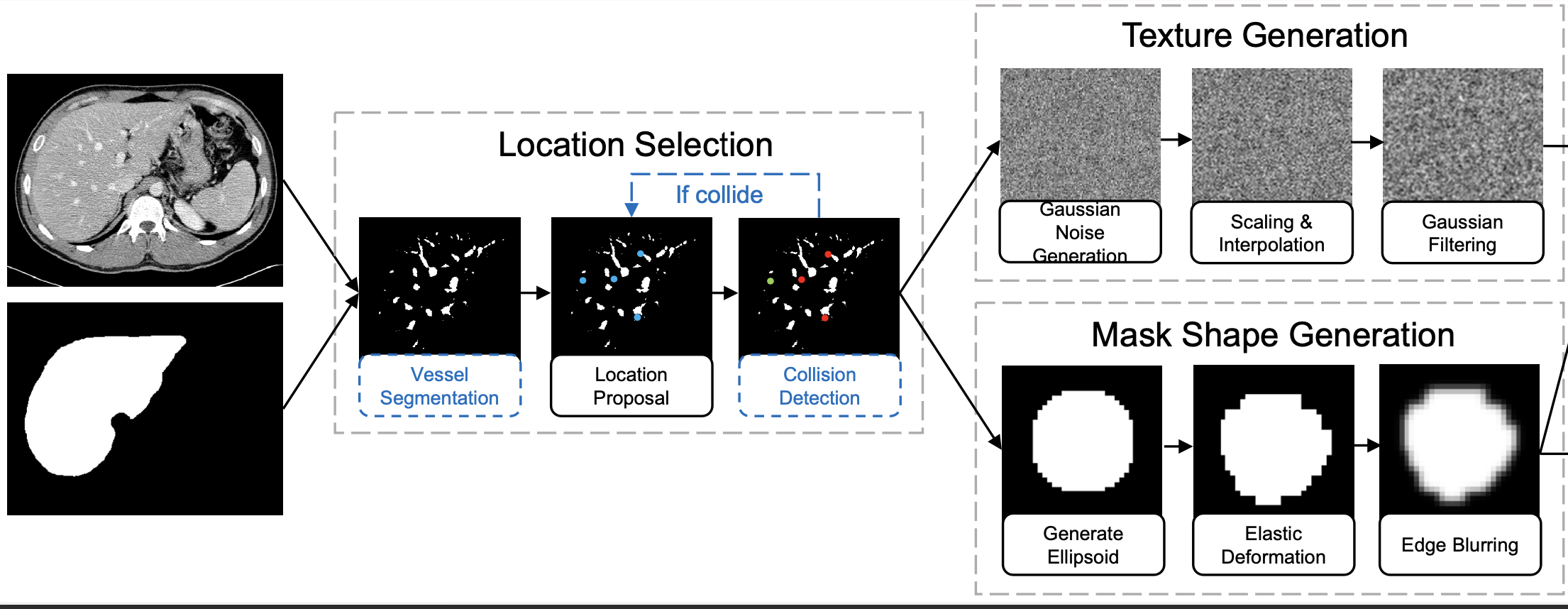
@inproceedings{liu2023clip,
title={Clip-driven universal model for organ segmentation and tumor detection},
author={Liu, Jie and Zhang, Yixiao and Chen, Jie-Neng and Xiao, Junfei and Lu, Yongyi and A Landman, Bennett and Yuan, Yixuan and Yuille, Alan and Tang, Yucheng and Zhou, Zongwei},
booktitle={Proceedings of the IEEE/CVF International Conference on Computer Vision},
pages={21152--21164},
year={2023}
}
|
|
arXiv /
code /
bibtex
@article{hu2023labelfree,
title={Label-Free Liver Tumor Segmentation},
author={Hu, Qixin and Chen, Yixiong and Xiao, Junfei and Sun, Shuwen and Chen, Jie-Neng and Yuille, Alan and Zhou, Zongwei},
journal={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
year={2022}
}
|
|
arXiv /
code /
bibtex
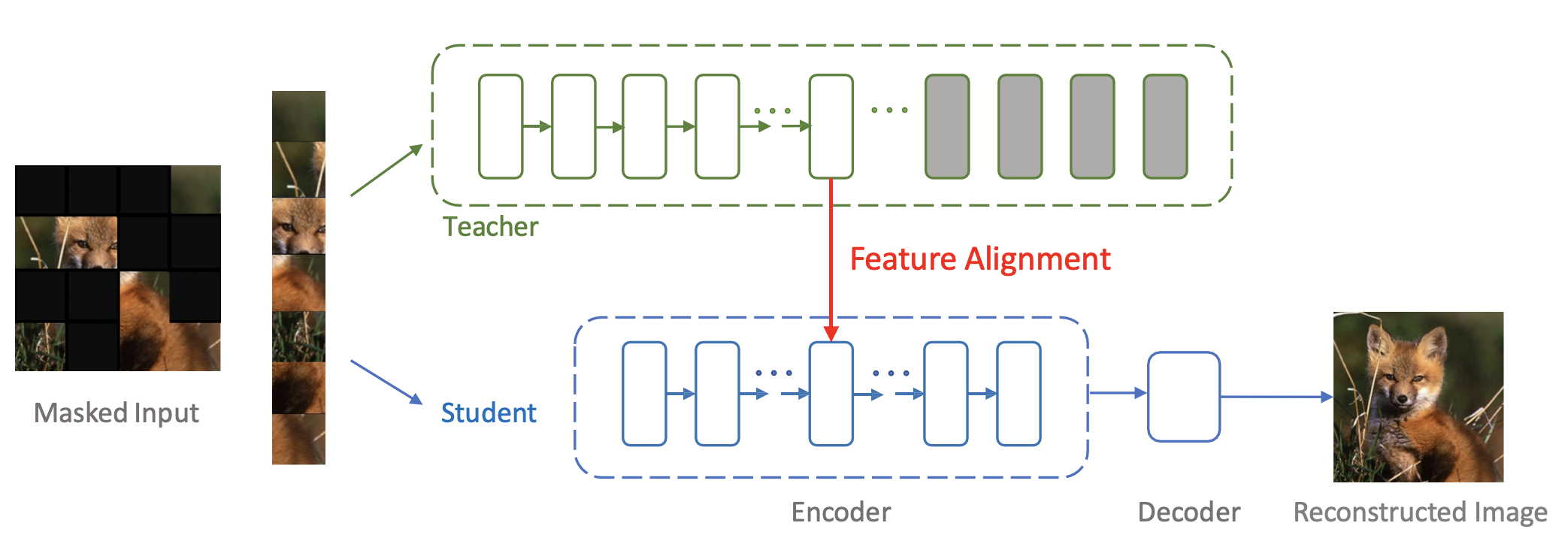
@article{bai2022masked,
title={Masked autoencoders enable efficient knowledge distillers},
author={Bai, Yutong and Wang, Zeyu and Xiao, Junfei and Wei, Chen and Wang, Huiyu and Yuille, Alan and Zhou, Yuyin and Xie, Cihang},
journal={arXiv preprint arXiv:2208.12256},
year={2022}
}
|
|
arXiv /
code /
bibtex
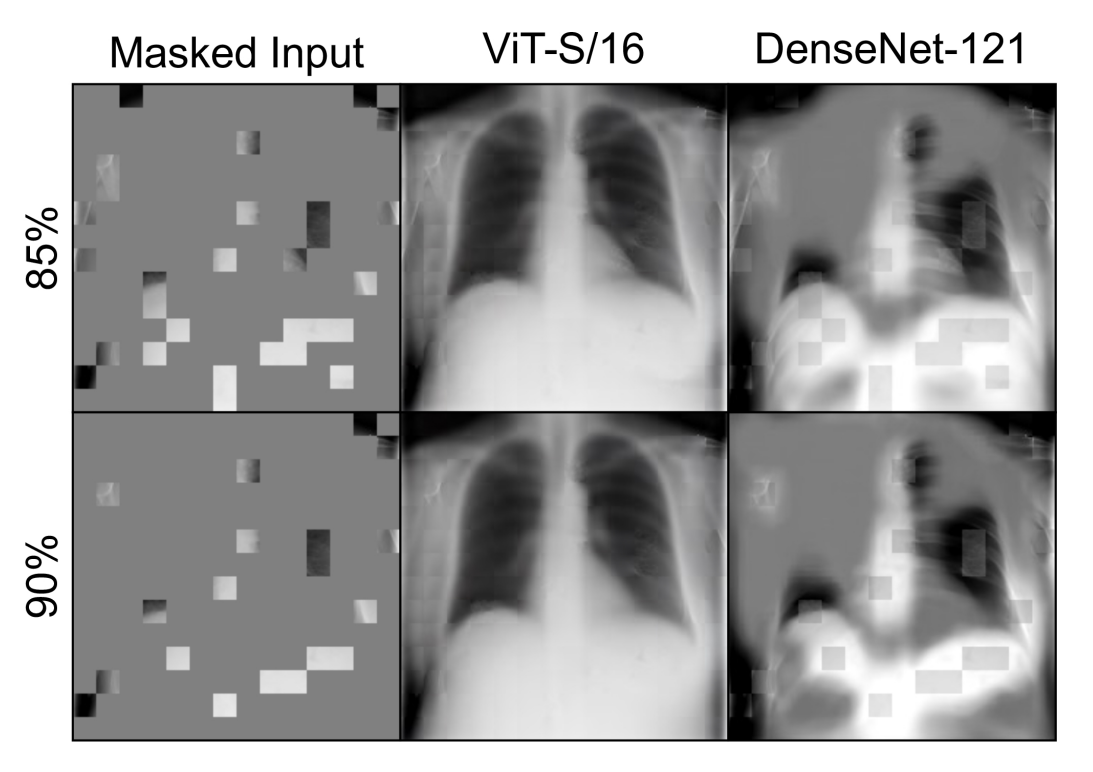
@article{xiao2022delving,
title={Delving into Masked Autoencoders for Multi-Label Thorax Disease Classification},
author={Xiao, Junfei and Bai, Yutong and Yuille, Alan and Zhou, Zongwei},
journal={arXiv preprint arXiv:2210.12843},
year={2022}
}
|
|
arXiv /
code /
bibtex
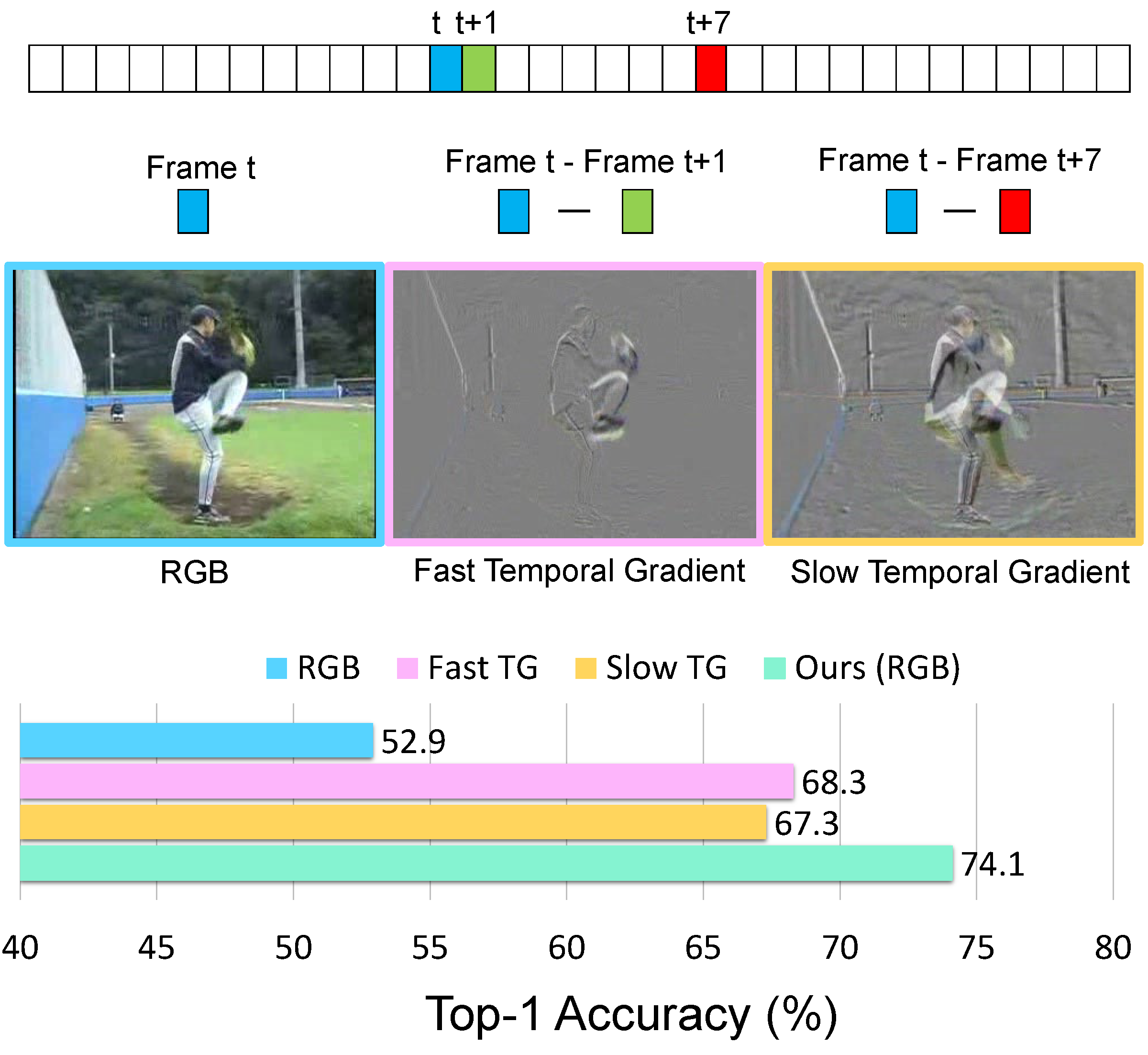
@inproceedings{xiao2022learning,
title={Learning from temporal gradient for semi-supervised action recognition},
author={Xiao, Junfei and Jing, Longlong and Zhang, Lin and He, Ju and She, Qi and Zhou, Zongwei and Yuille, Alan and Li, Yingwei},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
pages={3252--3262},
year={2022}
}
|
|
arXiv /
code /
bibtex
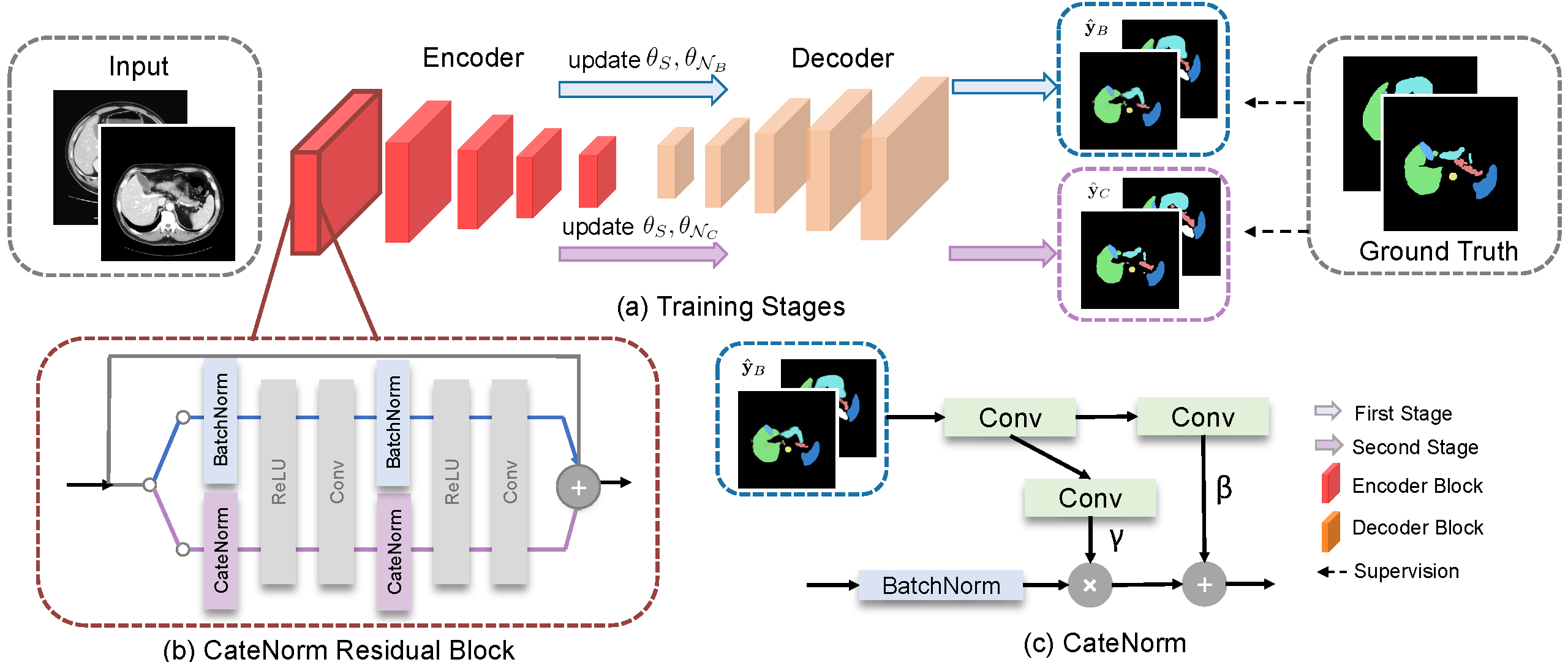
@inproceedings{xiao2022catenorm,
title={CateNorm: Categorical Normalization for Robust Medical Image Segmentation},
author={Xiao, Junfei and Yu, Lequan and Zhou, Zongwei and Bai, Yutong and Xing, Lei and Yuille, Alan and Zhou, Yuyin},
booktitle={MICCAI Workshop on Domain Adaptation and Representation Transfer},
pages={129--146},
year={2022},
organization={Springer}
}
|
|
arXiv /
bibtex
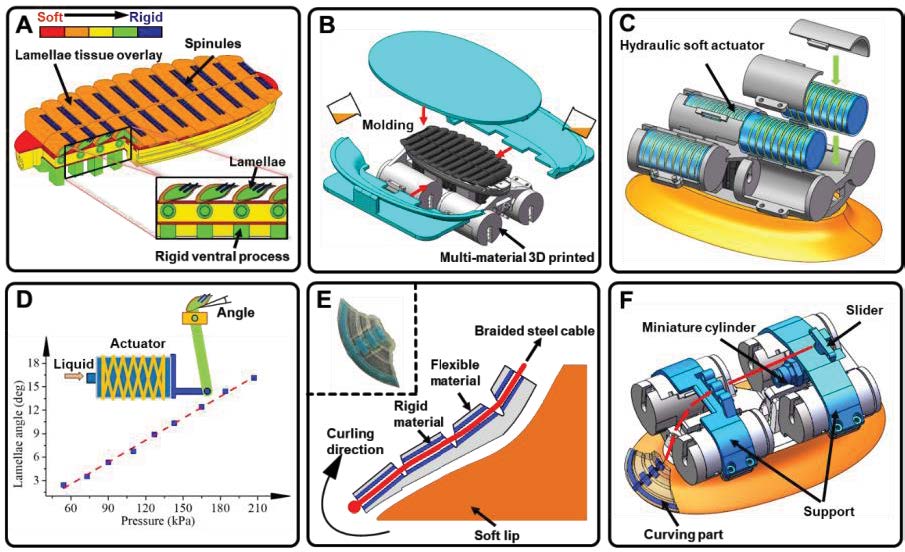
@inproceedings{wang2019bio,
title={A bio-robotic remora disc with attachment and detachment capabilities for reversible underwater hitchhiking},
author={Wang, Siqi and Li, Lei and Chen, Yufeng and Wang, Yueping and Sun, Wenguang and Xiao, Junfei and Wainwright, Dylan and Wang, Tianmiao and Wood, Robert J and Wen, Li},
booktitle={2019 International Conference on Robotics and Automation (ICRA)},
pages={4653--4659},
year={2019},
organization={IEEE}
}
|
|
|

|
|
|
Webpage template borrowed from Jon Barron |